This tutorial shows you how to work with the Create PDFs features in Acrobat 9. See what the all-new Acrobat DC can do for you.
Download a free trial of the new Acrobat.
Make your PDFs work well with Google (and other search engines)
Learn how to use Acrobat 9 to maximize the effectiveness of PDF documents you make available online.
By Duff Johnson – August 3, 2009

I probably use Google hourly, if not more often. I also search local and network hard drives looking for proposals, reference materials and so on. Whether I think about it or not, full-text search is a big part of how I do my job and live my life.
On many searches, especially for reference, official or printable content, lots of PDF files appear in my search results. As far as Google is concerned, a PDF document is just another web page, so search engines index PDF files, which represent a large volume of global page views. PDF is a factor in website SEO (Search Engine Optimization) in direct proportion to the volume of PDF-based content on that site.
So take a close look at the PDF file listings in your search results pages. After all, in many cases, this is how people decide whether or not to click onto your site.

Want to focus on PDFs in your search results? Simply add “filetype:pdf” to your search using Google, Yahoo or Bing.
Viewed through the prism of search results, many PDF files appear unprofessional and counterproductive –- at best. PDF authors and content managers should take the time to make their PDF files work right with search engines. Not only do PDFs optimized for SEO get more clicks, but for users seeking that file in the future, they save time, too.
How bad is the problem?
Most corporate and government websites contain PDFs, and those files often constitute the most important content on the site –- important in the sense that they must be easy to find and must look good when found. Product catalogs, pricelists, reports, brochures, manuals, documentation, fillable forms, archival records –- you name it and PDF files play a vital role in communications, the delivery of products and services, and in business administration itself.
I performed the following simple experiment, and you can do it, too.
I conducted a number of searches using conventional business terms, limiting the search in each case to return only PDF files. Example: “form server white paper filetype:pdf”, or “sheet steel research filetype:pdf”. Then I proceeded directly to Google's 10th results page (to avoid the very “best” content on the web), and started looking from there.
Your mileage may vary, but I'm happy to say that the overall quality of PDF search results seems to have improved significantly since I last reviewed this question. Back in early 2006, about 60 percent of public PDF files had meaningless titles that would never inspire a click. Today, I'm seeing around 30 percent of PDF files in that same condition. Of course, results vary wildly depending on your choice of search terms, but clearly, awareness that PDF files are part of web content -- just like HTML -- is catching on.
How do the PDF files on your own website look today? Google's Advanced Search makes it easy. Testing your own site is simple; just Google as follows: site:yoursite.com filetype:pdf. Here's how the PDF files on the Appligent Document Solutions site appear today (tsk, tsk).
Let's look at how you can maximize the effectiveness of PDF documents you make available online.
Every PDF needs a title
In terms of PDF files, the blue underlined text in Google's search results comes from one of two places. First, Google looks in the "Title" document information field. If it finds nothing, Google's indexer tries to guess the document's title by scanning the text on the first few pages. This usually doesn't work, producing incorrect and improperly formatted results.
Of course, if the indexer DOES find text in the Title field, it will use it –- regardless of whether that text is garbage or not. As a result, there are millions of PDF files on the web with gloriously informative titles such as: “Brkg2RechBrntGrtA122a.qxd”. Well, apart from the fact that the designer used Quark, there's nothing else I know (or care to know) about this document from looking at the search results.
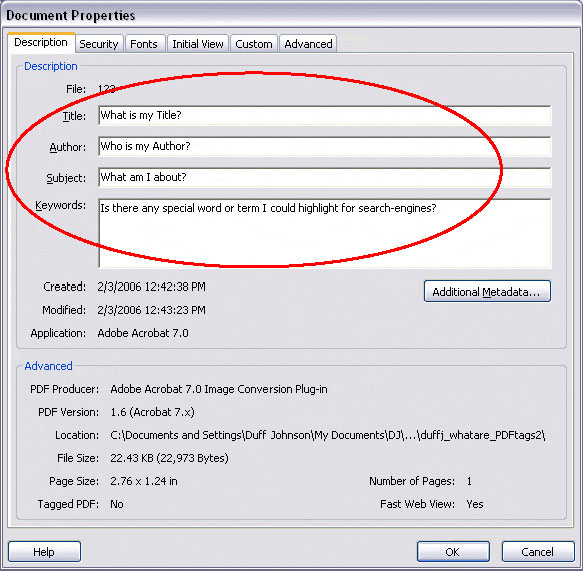
Be sure your PDF files' document information fields correctly represent your document.
To check a PDF file’s Title information in Acrobat, type a Control-D, or go to the File > Document Properties menu, then click the Description tab, where you can add or correct PDF title, author and other metadata as desired. There are a variety of third-party server tools for reading and writing PDF metadata to support or process large collections of PDF files.
While it's the simplest thing for PDF authors to include a meaningful title, real-world search results clearly demonstrate that many leave their title fields empty, bogus or just don't bother at all. As in the above example, many authoring applications simply place filename information in the Title field, providing a search-results "look and feel" that ranges from cryptic to completely meaningless.
Whatever else you do when posting PDF files for public view, quality title metadata is essential.
Ensuring that each and every PDF file contains a valid and meaningful title is the single easiest way to ensure that search results will display information that's vital to getting users where they want to go. Leave PDF titles unattended, and the certain result is slower, less-reliable searches for every user, every time they search.
Other considerations
PDF Specification: In early 2006, Google couldn't index PDF files above the 1.5 specification. As of July 2009, Google indexes content from even Adobe's latest specification version -- 1.7 Adobe Extension Level 3 (Acrobat 9.x).
File-size limits: No search engine I'm aware of indexes every word in every PDF file. While in 2006, Google didn't index PDF files larger than a couple of megabytes, today I observe Google indexing text from PDF files of up to 10MB. Much larger, however, and Google simply ignores the PDF file entirely.
Of course, it's also possible that Google's limiting factor on PDF files is based on the time required to download the file from a given server. If so, then faster websites with larger pipes will get more of their large PDF files indexed than the same size files would get on a poorly performing server.
Text-volume limits: File size is one way of limiting content, but for search engines, it's the text itself that really counts. PDF files can be packed with megabytes of pure text.
While I don't know Google's current upper limit on text it's willing to index, I did test the Report of the 911 Commission, one of the most popular PDF-based reports on the web. At 585 pages, the plain text is 1.3 megabytes, and every word is indexed. If your files are a lot larger, post and test them first, by searching for a unique text string towards the end of the document.
If posting large PDF files (due to the size of the included images, for example) and it's critical that Google indexes all of the content, consider posting by chapter. This way, Google is less likely to stop indexing at, say, page 57 of a 112-page document. OCR: Many PDF files are simply scanned pages with no searchable text. Until recently, these PDF files were effectively invisible to search engines because, well, there's no text to search.
As of November, 2008, Google OCRs the image-based PDF files it downloads, no extra charge. This means that even plain, scanned pages will be searchable, even if the owner didn't explicitly make them so. So far as I know, Google is (still) the only search engine to offer this feature.
Now Google's OCR isn't the greatest; it's optimized for speed rather than accuracy. You can do this yourself, and get better search results, by running and quality controlling your own OCR, then posting the results.
Security: There are many reasons to secure PDF files against unwanted changes, or to disallow the extraction of content. Done wrong, it's possible to inadvertently block search engines from indexing text in a secured document. To ensure that secured PDFs are searchable, be sure to check the "Enable text access for screen-readers" box when encrypting your files. Additionally, when selecting Acrobat 6.0 compatibility or higher, be sure to "Encrypt all document contents except metadata" to ensure PDF metadata is available to search engines.
Content reading order: Take a close look at search results showing your search terms in context, and you may find oddly spaced, duplicate or jumbled text. If you take Google's offer to “View as HTML”, as I often do, the text often looks REALLY bad, with disjointed paragraphs, headings demoted to text and tables, columns and sidebars hopelessly confused.
If the way search engines retrieve and display search results matters to you, or if you must adhere to accessibility or Section 508 standards for web content, plan to get familiar with reading order in PDF-based content and tagging, the structure information (headings, lists, tables, etc), of PDF files.
To ensure a quality representation in search results, PDF creators (software and personnel alike) must ensure text is correctly ordered for extraction purposes. Generally speaking, PDF files with sophisticated layouts, fonts and text effects (i.e. typical marketing literature, or high-value reports) are the most likely to have content ordering and structuring problems, whereas simpler documents produced in Word, InDesign and the like tend to have valid (or at least, better) structure.
A deep dive into content order and tagging in PDF files is beyond the scope of this article, for ensuring correct content ordering is not a simple checkbox option. However, paying attention to content order can dramatically improve the way search results are displayed. Both content order and tagging may be addressed in Adobe Acrobat Professional. (View > Navigation Panels > Tags, and View > Navigation Panels > Order)
To begin defining content order in Acrobat Professional, first find out whether your file is Tagged. (Control-D keyboard shortcut, then check the "Description" tab)....
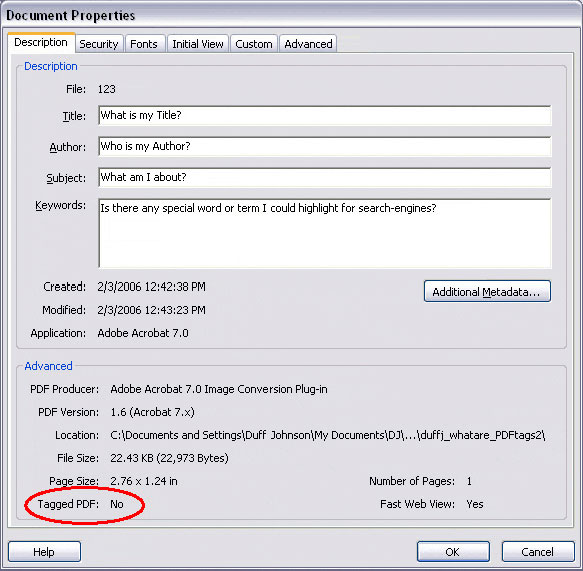
This little tell tale is prima-facie evidence of inaccessible content. Not only should Tags say "Yes", but the tags should be validated, too.
If your PDF isn't structured and tagged, you can quickly tag it using the Advanced > Accessibility > Add Tags to Document command. Once tags have been added, view how the content is currently ordered, via the Content panel, or else start from Advanced > Accessibility > TouchUp Reading Order. To make your PDF files truly accessible and maximize their SEO value, validate the tags, ensure images have good alternate text (also indexed by search engines) and ensure tables, lists and other structure elements are in good order.
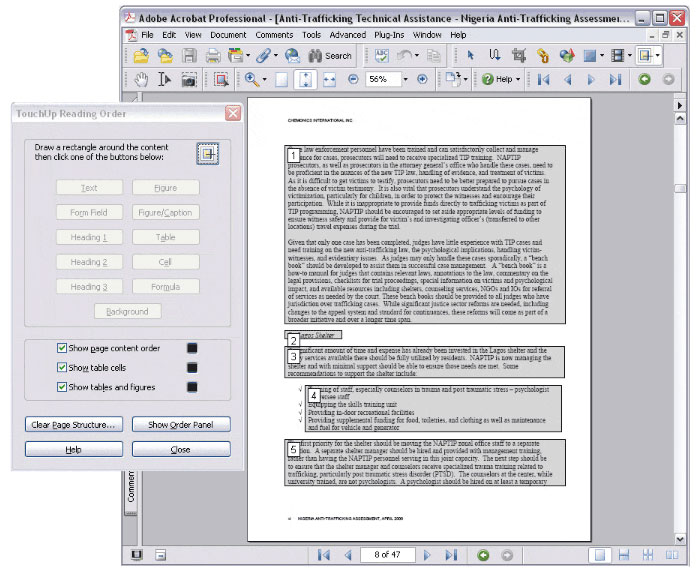
Get the reading-order right, and so will Google. Why does this file need help?
Content: Just like any web page, PDF documents add to the SEO value of your site when they contain keywords in prominent places and enclosed in heading (H1, H2) tags in the PDF files. Be sure to include links in the PDF files back to your own website. Users who post your PDF files on other servers will be posting links back to your own site -- how neat is that?
In general, think of PDF files as web pages that users can take with them offline, and you'll start to get lots of ideas about how to make your PDF files work for your site, wherever they are.
Name that file! A PDF file's name is often a vital part of content-management strategies. To ensure the filename also serves search engine optimization interests as well, try to give your files meaningful names that include keywords or reflect the file's Title.
What about other engines?
Google isn't the only search engine out there, and while it is (currently) dominant, other players boast a variety of strengths. Yahoo, the next-biggest player also indexes PDF files, and displays search results using almost precisely the same look and feel as Google, including a “View as HTML” option. In a brief review, I could not discern a substantial difference between the way Google and Yahoo displays PDF-oriented search results.
With just over eight percent of searches worldwide in its first full month after launch, Microsoft's Bing search engine is worth a look. Like Google, Bing indexes PDF files irrespective of version. Unlike Google and Yahoo, Bing does not provide a “View as HTML” option for PDF-based content.
As might be expected. all three engines rank PDF files using very different algorithms. Properly structured PDF files should improve search performance on any search engine, not just Google.
Conclusion
Most organizations posting documents to their internal networks or to websites want those documents to be easily found by others. Corporate intranets rely on search engines to index and retrieve all manner of internal documents everyday.
To the extent that PDF files comprise a meaningful volume of your searchable content (and you wouldn't have read this far unless they do), you owe it to yourself to make sure your PDF files will look their best under the relentless gaze of the search engines.
Key Takeaways:
- Verify each PDF file's "Description" (in Document Properties) before posting. Make sure that all PDF files have meaningful Titles, if nothing else.
- Add structure and proper tags to PDF files to improve the quality and appearance of search results.
- File-size limits may apply. Try to ensure that PDF files posted online are as small as possible, to minimize the chance that search engines will give up and fail to index the document.
- If you're posting scanned documents, OCR them prior to posting.
Products covered: |
Acrobat 9 |
Related topics: |
Create PDFs |
Top Searches: |
Print to PDF create PDF convert HTML to PDF convert scans to PDF convert Word, Excel or PowerPoint to PDF Convert PDF to JPEG |
Try Acrobat DC
Get started >
Learn how to
edit PDF.
Ask the Community
Post, discuss and be part of the Acrobat community.
Join now >
6 comments
Comments for this tutorial are now closed.
Lori Kassuba
2, 2014-02-06 06, 2014Hi Ken - good luck with your project!
Lori
Ken Stringer
4, 2014-02-05 05, 2014Lori: Thanks for your help, I appreciate it.
Lori Kassuba
6, 2014-02-04 04, 2014Hi Ken Stringer,
Unfortunately this appears to be known issue with Google Drive:
https://productforums.google.com/forum/#!msg/drive/xxx3qtRbA2w/ukwiQ4GgWJQJ
Is this what you’re using?
Thanks,
Lori
Ken Stringer
7, 2014-01-30 30, 2014Here’s one: http://childrenshealthcare.org/wp-content/uploads/2014/01/1988_Spring-clearscan.pdf
This was a printed document scanned into a pdf (each page is a jpg, however). No text was searchable at that stage, so I used Acrobat XI to make the text within the document searchable. That’s the way you see it now. I assumed that this conversion process would make it searchable with Google too, but it isn’t. I notice that the pdf has a box in the upper left indicating that each page is still a jpg, so I imagine this is the problem. The conversion from image to text is apparently only some kind of overlay trick that Acrobat can do but doesn’t change the basic jpg structure. And I guess that’s why Google can’t read it. Any further insight you can give me would be much appreciated.
Lori Kassuba
6, 2014-01-30 30, 2014Hi Ken Stringer,
Any chance you can post an example URL?
Thanks,
Lori
Ken Stringer
8, 2014-01-28 28, 2014Right. It doesn’t find the document which contains the searched-for word either, much less the actual text within the document. I really don’t expect it do more than the former and that would be great.
Lori Kassuba
2, 2014-01-28 28, 2014Hi Ken Stringer,
Are you saying that Google doesn’t find the text within the PDF after OCR or the Title?
Thanks,
Lori
Ken Stringer
9, 2014-01-26 26, 2014Yes, it was a very interesting article. However, I didn’t find the answer to my problem in it. I manage a web site that has quite a few pdfs on it and uses a Google Custom Search for visitors to search for specific words and phrases. Most of the pdfs were produced in MS Word and then saved as pdfs. Recently, though, I have converted the images in other documents that were scanned and saved as pdfs with an Acrobat program which uses OCR to read the images as text. Now one can search WITHIN the document where one couldn’t before. When uploading to the web site, though, Google still does not find them. I made sure the files had titles. Any thoughts?
Joao Dias da Costa
1, 2013-10-08 08, 2013The article was of great use for me. Good quality information and writing. Congratulations and Thank you very much!
Communica
9, 2013-09-29 29, 2013Had no idea that Googlebot had OCR capabilities. Great article. Thank you very much.
Comments for this tutorial are now closed.