Offer search tools a helping hand



More and more Web-based materials are available as PDF documents. Make sure your files contain what search engines need to catalog your files.
If you stop to think about a PDF file for a moment, you’ll realize there is much more to the file than the words, images and page layout you see on your screen or send to your printer. A wealth of descriptive information lies beneath the document’s surface, waiting to be processed and searched.
How search engines look for PDF files
Modern search engines can access information from a PDF file. When search tools index PDF files, they can get the text from the PDF information fields, such as a document title and additional keywords. If the document creator didn't enter that information, the engine may attempt to generate a title, may use the file name of the document, or use the first words of the file’s contents.
For instance, Google looks at the Title description field, such as the Title field’s content Prepare, Preflight and Print (Figure 1). If I hadn’t included a title, the path leading to the file’s location is used as the search return instead.
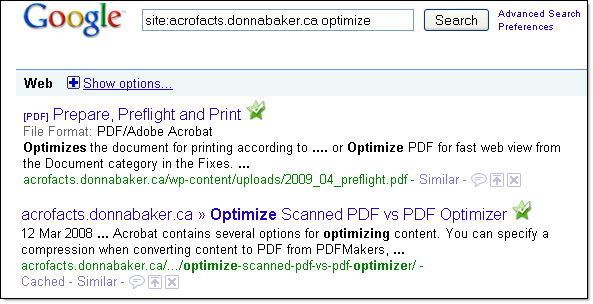
Figure 1: Search returns display the content available to the search engine.
The scoop on metadata
Descriptive data about the information in a PDF file is called metadata. Some types of metadata, such as color profiles, are used for printing. Other types of metadata, such as font descriptions, are used both for printing and displaying the content in the file onscreen. Some metadata types include content that search engines and PDF search tools use for indexing the content of the PDF files.
Embedded metadata
PDF documents created in Acrobat 5.0 or later contain document metadata in XML format. Metadata includes information about the document and its contents -- such as the author’s name, keywords and copyright information -- that can be used by search utilities and engines.
The eXtensible Metadata Platform (XMP) embeds information about a document within its content. Applications that support the platform can use the common XML framework to standardize the creation, processing, and interchange of document metadata across publishing workflows. You can save and import the document metadata XML source code in XMP format, making it easy to share metadata among different documents. You can also save document metadata to a template to reuse in Acrobat.
View document properties
Basic information about a document is contained in the Properties. Choose File > Properties to open the Document Properties dialog, which displays the Description tab by default (Figure 2).
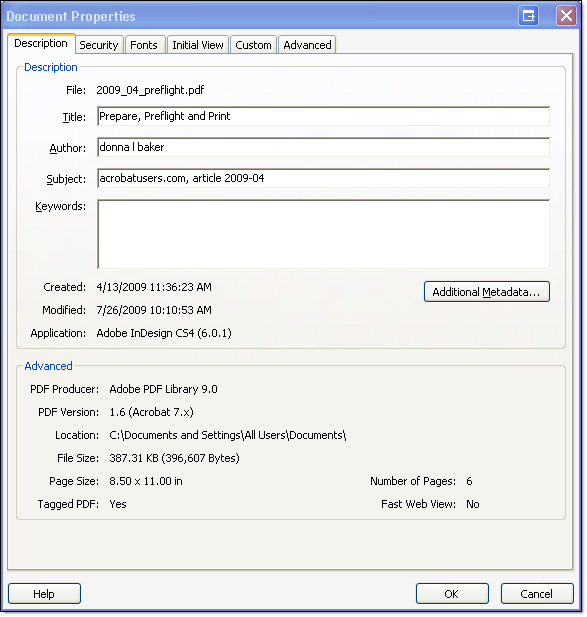
Figure 2: Basic information is contained in the Document Properties.
By default, the only piece of descriptive data attached to the file is the File name itself. Add additional information to the Document Properties as required. At a minimum, assign a Title to the Document Properties to use as a basic tag for searching.
Look at advanced metadata
There are a number of advanced data schemas associated with a document. Click Additional Metadata on the Document Properties dialog box to display the Additional Metadata settings; the dialog box uses the file’s name. Use the listings in the column at the left of the dialog box to display settings panels in the dialog box. Many of the listed settings are used for managing image content.
Tip: The Description settings include the fields shown in the Description tab of the Document Properties dialog box.
Click Advanced to show the metadata schemas associated with the PDF file and then click the icon to the left of the heading name to display its contents (Figure 3). The listings include PDF properties, XMP properties, Dublin Core properties (a set of 15 generic XML tags for tracking and cataloging web pages and creating metadata) and other image and file standards’ properties.
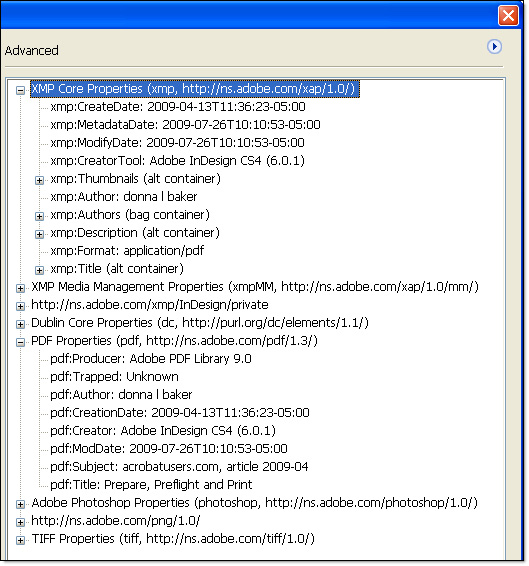
Figure 3: Advanced metadata is organized by schema.
Write once, reuse often
If you look at the Description dialog box shown in Figure 4, you’ll notice drop-down arrows to the right of the fields. Any content typed into a field in the dialog box for a document that supports XMP is stored on your system. Click an arrow to display the content entered in the associated field and select an option.
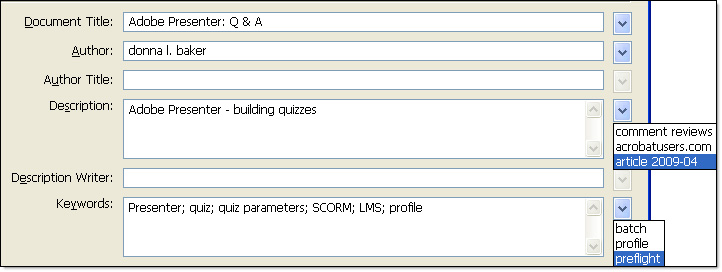
Figure 4: Add content manually or from a list of previous field content.
Note: The image shown in Figure 4 displays multiple content options.
You can save all the information about a file and reuse it as often as you like by saving the metadata as a template. If you regularly use certain types of information -- such as author images in PDF format -- you might want to save the metadata template to reapply, for example. Metadata templates save time and decrease error.
Click the circled right arrow at the top right of the dialog box to display a menu for managing metadata files (Figure 5). Choose an existing template or create a new template from the content entered in the Additional Properties dialog box.
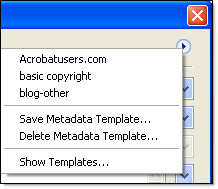
Figure 5: Metadata templates are included as part of the metadata management system.
Select an existing template, save a new template, or delete one from your collection. Click Show Templates to open the template folder on your hard drive, convenient when you want to read the actual XML of the template, or want to send a copy to someone else to use.
Design a metadata tagging system
A solid metadata design is a must, especially if your workflow entails working with hundreds of documents and PDF images. Be sure to share the information with those working with your files. Your efforts only become a working system when users understand how you’ve defined content; otherwise, it’s a waste of time to include metadata descriptions.
Keep these ideas in mind when designing a metadata scheme:
- Use a descriptive title for the documents.
- In a large organization, use the Author field to specify a workgroup or department, such as MarComm or Operations.
- Standardize the categories for the same information. Decide how to handle the Subjects vs. Keywords situation -- be sure a term is used for only one or the other field. Otherwise, searching for “baboon” as a subject will return only those results, not those files containing the term as a keyword.
- Synchronize the use of subjects, keywords and authors. You might use “sales report” as a Subject for a document, for example, and the date range as a keyword. Take it further by defining the Author as a type of sales or sales region; add the individual sales representative’s name as a keyword, or define a custom metadata object.
- Many organizations, such as law firms, use document part numbers; add the document number as a keyword.
PDF-indexing challenges
Documents that are scanned or converted to PDF from some applications can present tough indexing problems. Watch out for these issues:
- Text in a scanned document may not be captured; a graphical image of the text can’t be indexed
- A scanned file that has been captured using optical character recognition (OCR) may have a significant number of errors in the interpretation. As a result, search terms might not be matched even though the words are in the original text, or search terms may be falsely matched if the text was interpreted incorrectly.
- A PDF file generated by some programs may contain partial words resulting from hyphenation or incorrect coding of extended characters or ligatures. The mangled word won’t match a query even though the words exist in the original text.
- A document with multiple columns converted to PDF may not have the appropriate text flow. Unless the file is tagged to define the reading order the text isn’t identified in the correct sequence. A search engine may fail to match a phrase query because the appropriate text relationship isn’t stored in the PDF file.
Tips for optimizing PDF files for searches
Search engines can generally read and index the content of a PDF file that contains text. However, the content may be restricted to the first n hundred or thousand characters. Here are some tips for ensuring your PDF files are indexed as accurately as possible:
- If you want a search engine to find your content based on keywords or key phrases, be sure you include those terms in prominent locations in your PDF file, such as the page titles and table of contents.
- Break up your PDF file into several documents to bypass the search engine’s restricted number of indexed characters. Each component document can then be indexed to the search engine’s capacity producing a greater overall amount of content included in the index.
- Create an abstract of the PDF in XHTML and link it to the PDF file to maximize exposure of your keywords and key phrases.
Try Acrobat DC
Get started >
Learn how to
edit PDF.
Ask the Community
Post, discuss and be part of the Acrobat community.
Join now >
0 comments
Comments for this tutorial are now closed.
Comments for this tutorial are now closed.