This tutorial shows you how to work with the Scan and Optimize features in Acrobat 9. See what the all-new Acrobat DC can do for you.
Download a free trial of the new Acrobat.
Troubleshoot scanning and OCR in Acrobat 9
Learn how to scan paper documents to PDF files and store them with your other resource material using Acrobat 9.



Document scanning and OCR workflows sometimes include as much art as they do applying processes and commands. In this article, I’ll describe ways you can improve your scan output.
Often older source documents, maps and artwork are in poor condition. In addition to being physically fragile, the documents may have lost contrast, color definition and clarity.
You can improve scan quality in several ways, depending on your intended use for the material. If you’re scanning an old document or map to preserve a digital copy, color definition and clarity are likely more important than contrast. On the other hand, contrast is the most important feature for content you intend to capture using OCR.
Tip: If you intend to use the scan results as a PDF image, you’ll have more control when enhancing scan results in Photoshop.
Start the scan (and customization) process
Acrobat 9 offers a feature to scan content directly to a PDF file, using a number of settings and scan options. When you aren’t sure how your item will scan, perform a test scan using the default settings, evaluate the results and then rescan with applied filters and customizations.
Click the Create PDF task button to open the menu, choose From Scanner and then select a text or image preset according to your document. Available presets include Black & White Document, Grayscale Document, Color Document and Color Image (Figure 1).
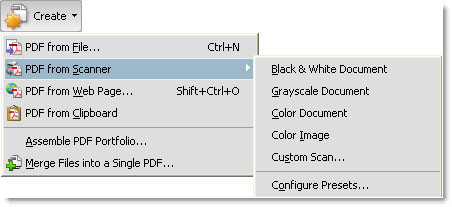
Figure 1: Select a scan preset in Windows.
The Configure Presets dialog box opens. The basic choices for configuring and adjusting a scan and/or preset are straightforward, and dependent on the selected scanner.
Note: A preset list isn’t available on Mac. Click From Scanner to open the dialog box directly.
To optimize the document’s content, particularly for images, drag the Optimization slider left (to decrease) or right (to increase) file size and quality (Figure 2). The default option, roughly at the center of the slider, is appropriate for basic scanning and OCR. Increase the quality for an image requiring significant correction according to your scanner’s capabilities prior to OCR.
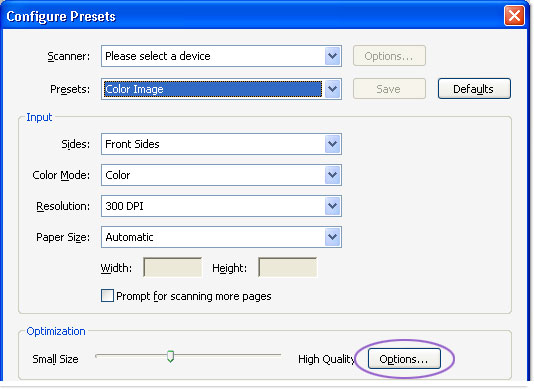
Figure 2: Choose an optimization level according the desired quality versus file size.
Try the built-in filters
Click the Options button (circled in Figure 2) to open the Optimization Options dialog box where you set compression and filter settings (Figure 3).

Figure 3: Choose filters to improve the appearance of your scans.
Acrobat offers several optimizing filters to adjust or correct your scan results; before and after examples are shown for each filter:
- You may be trying to scan a copy of another file that is out of visual alignment. Deskew rotates a skewed page, so that it’s vertical (Figure 4).
The default setting is Automatic.

Figure 4: A skewed image (left) is readily aligned using the filter (right).
Use Background Removal for grayscale and color pages to brighten nearly white areas to appear white, resulting in clearer scans (Figure 5). The default is Low; you can also choose Medium and High options.

Figure 5: Correct a common fault by changing the darkened background (left) to white (right).
Remove the black edges sometimes seen on scanned pages using the Edge Shadow Removal filter (Figure 6). The default is Cautious; an aggressive option is also available for very heavy shadow.

Figure 6: Some scanned pages show an edge shadow.
Despeckle removes black marks from the page. Low is the default; you can also choose Medium and High. Be careful using the higher settings as the characters on the page may become blurry and indistinct (Figure 7).

Figure 7: Use the Despeckle filter on a page (left) to remove random artifacts from the page (center) without blurring the character edges (right).
Descreen removes halftone dots, like those from a scanned newspaper (Figure 8). By default, Acrobat applies the filter automatically for grayscale and RGB images 300 ppi or higher.

Figure 8: Pages scanned from media such as a newspaper may display halftone dots resulting from the printing process used to create the source content.
Halo Removal removes high-contrast edges from color pages (Figure 9). The default setting is On.

Figure 9: Remove the excessive contrast from color pages (left) using the Halo Removal filter (right).
Why use OCR?
You’ll need to capture the content if you intend to use a scanned document further. If you simply need a page to include with other printed material, there’s no need to perform OCR on it. For example:
- The document is intended to become part of a searchable document collection.
- You intend to repurpose, reuse or extract some of the content.
- You need the document available for users working with screen readers and other assistive devices.
Recognize the page’s text
Whether you’ve got a document you scanned earlier, an image of a page from another location, or are configuring an initial scan process (using the dialog box shown in Figure 2), you can choose from a number of output styles, described in Table 1.
| OCR Option | Features |
| Searchable Image | Compress the foreground and place the searchable text behind the image. Compression affects image quality. |
| Searchable Image (Exact) | The page foreground remains intact while the searchable text is placed behind the image. |
| ClearScan | The ClearScan option rebuilds the page, defining the page content as discrete text, fonts and graphics. |
Table 1: Choose the appropriate OCR format.
Note: If you select one of the searchable image options, you can select one of four options from the Downsample Images popup menu—anywhere from 600 down to 72 dpi. Be careful: Although downsampling reduces file size, it can also result in unusable images.
How scan choice and page content interact
You’ll have good OCR results when your document uses a clear, strong font and significant contrast between the text and background. On the other hand, if your source document is a scan of an old photocopy, uses decorative fonts or strong background images or color, you may find it simpler to rekey the document than to try to capture and correct all the text.
Look at this final example, incorporating most of the items that are sure to wreak havoc on OCR (Figure 10). The source document, an attractive restaurant menu, uses a decorative font overlying an interesting background.

Figure 10: OCR results leave much to be desired when the source document is too complex.
After applying the Exact Image OCR choice, I exported the page as RTF with less than stellar results. The overlay on Figure 10 shows the less than stellar OCR results for the page!
Products covered: |
Acrobat 9 |
Related topics: |
Convert JPG to PDF online, Scan and Optimize |
Top Searches: |
Convert JPG to PDF onlineCreate PDF convert scanned documents to PDFs get started with Acrobat DC |
Try Acrobat DC
Get started >
Learn how to
edit PDF.
Ask the Community
Post, discuss and be part of the Acrobat community.
Join now >
0 comments
Comments for this tutorial are now closed.
Comments for this tutorial are now closed.