This tutorial shows you how to work with the JavaScript features in Acrobat 9. See what the all-new Acrobat DC can do for you.
Download a free trial of the new Acrobat.
Custom document search using JavaScript and Acrobat 9
Learn how to build advanced search features into your own documents or document sets using JavaScript and Acrobat 9.
By Thom Parker – June 9, 2009


Acrobat has a powerful and feature-rich Search Engine. The search engine options include the standard text search features, such as case sensitivity, as well as special PDF options, such as searching the bookmark labels. There are even more advanced features, such as creating multiple dependencies and searching previous results. There is even a way to build search indices that makes searches faster and includes multiple PDFs. But what most people don’t know is that this search engine is almost completely controllable from Acrobat JavaScript, so you can build advanced search features into your own documents or document sets.
How it works
From the Acrobat or Adobe Reader user interface, the user selects the "Edit > Search…" menu item. This menu item displays the Search Panel (Figure 1), which contains a host of options for controlling the search. These same options can be controlled through the "Search" object in the Acrobat JavaScript DOM. In the figure, the options are set up to search the current document for any text containing the words "menu" and/or "list." The search will look in both the PDF content and the bookmarks.
After setting up the search options, the user presses the "Search" button to start the actual search. When the search is complete, Acrobat displays a search results panel (Figure 2). The first set of results is in the bookmarks, the second is in the PDF page content. This is also how the search works in JavaScript. There is a function to start the search, and when it is complete, the results panel is displayed to the user. From a scripting perspective, it would certainly be more
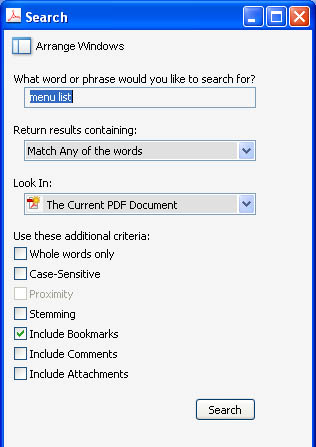
Figure 1 – Setting up search options
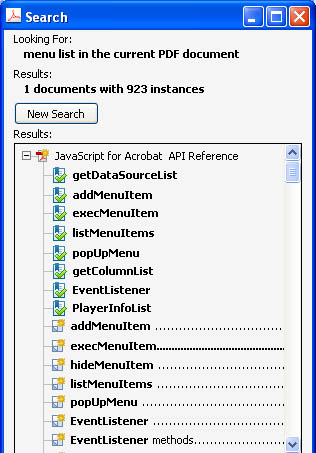
Figure 2 – Bookmark and content search results
useful to make the search results directly available to the script, but alas, this is not the case. The script has no access to the search results. The search object was designed on the premise it would be used to provide simple but powerful search interfaces to users, so we are limited to using it in only this way, which isn’t necessarily a bad thing.
A simple example
To get started, let’s look at a simple script for running a search. Open a PDF, for example the Acrobat JavaScript Reference. Now open the Console Window, enter and run the following code:
search.matchCase = false;
search.wordMatching = "MatchAnyWord";
search.bookmarks = true;
search.query("menu list","ActiveDoc");
The first three lines set up the search object options to match the options used in Figure 1. The last line starts the actual search using the "search.query()" function. The first input to this function is the search string and the second input is the location to search. In this case, it’s searching in the currently active document, which is the PDF the user is viewing. There are many variations on how a search can be run. In fact, the search object actually provides more options than are available from the user interface. To get a complete list of these options, look up the search object in the Acrobat JavaScript Reference.
One possible use for the above script would be for implementing a dynamic index. For example, rather than a word in the index providing explicit page numbers, the word itself would have a link over it. When the user presses the link, it runs a script similar to the script above. This technique allows information to be added and removed from the index without the document developer ever having to remake the index.
Advanced usage
The most common usage scenario for the search object is to provide specialized search tools for a library of documents, such as a set of documents on CD. For example, let’s say all the forum posts for this month at www.acrobatusers.com were converted into a set of PDFs and distributed to users on a CD, one PDF for each forum category. The developers of the CD want to provide an easy-to-use search mechanism customized to this set of documents.
The first thing the developers need to do is create an index catalog file. This is a special type of file Acrobat uses to make searches more efficient, i.e., Acrobat looks through the index file rather than searching the PDF. In Acrobat 9, this feature is accessed from the "Advanced > Document Processing > Full Text Index with Catalog…" menu item. This menu item displays a dialog that builds an index file for an entire folder of PDFs. In our example, we’ll need both individual index files for each forum category, i.e., each separate PDF, and for all the PDFs together. To do this, the individual PDFs associated with a category will need to be placed in separate folders. This gives us the ability to narrow a search to one specific forum category, or to broaden it to all the documents, and to do it in an efficient manner.
Using an index for a search
There are two ways to use the search object with an index. The path to a specific index file can be passed into the search.query() function, or the query function can search against a list of previously defined indexes. For example, the following code performs a search using the index file for the JavaScript forum:
search.query("menu list","Index","/G/Catalogs/JSforum.pdx");The last input parameter is the full, device-independent path to the catalog file. In this case, "G" is the CD Drive, but for most situations the full path will not be readily available. We’ll need to derive it from the current file’s path. When working with index files, the relative path structure between the index and the PDF must remain the same. So if we know the location of the PDF we know the location of the index file. The following code demonstrates a general method for finding the path to our index file from the current document:
// Split the file path into an array
var aPath = this.path.split("/");
// Remove the last element, which is the file name
aPath.pop();
// Join the path elements back together and add the index file
var cIdxPath = aPath.join("/") + "/Catalogs/JSforum.pdx";
search.query("menu list", "Index", cIdxPath);
This code can be used from a button or link on a PDF file, given of course that the path modification is correct for the PDF and index locations.
The other, more general method for searching an index is to use the Active Index List. The search object keeps the list of the active indexes in the search.indexes property. Unfortunately, this property is privileged. It cannot be used from a document script, so its use will not be covered in this article.
Building the user interface
The next step in this process is to set up a search interface for the user. One of the easiest ways to do this is to create a PDF with all the controls the user needs to do searches specific to the documents on the CD. This could be a separate PDF or part of a larger introduction/index document on the CD, something that pops up automatically when the CD starts up.
To create the interface, we need three elements (Figure 3)-
- A text box for entering the search string.
- A button for starting the search.
- A combo-box for selecting the scope of the search, i.e., in which forum category to search.
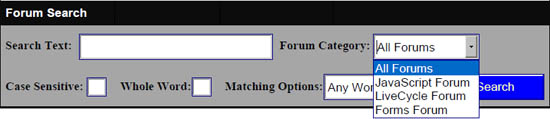
Figure 3 – User interface for a custom search. A few of the search object options provided.
In this interface, a few search object options, such as case sensitivity and word matching, are included as extras, but they aren’t necessary for running the basic search functionality. Many more options can be included, depending on what the developer wants to expose to the users.
The script
All of the functionality is in the search button, which runs the script shown below. Notice that the first thing the script does is to test the search text. The search will only be run when the search text is not empty. The next part of the script uses the location of the current PDF to determine the full path to the index files, exactly the same setup as shown in the previous script, except that the combo-box selection is used to determine the specific index path. Then, the search options exposed in the user interface are set, and finally the actual search query is called.
var cSearchTxt = this.getField("SearchText").value; if(!/^\s*$/.test(cSearchTxt)) {
// Create first part of path to index file from this file
var aPath = this.path.split("/"); aPath.pop(); var cPathRoot = aPath.join("/");
// Determine Index to use with search
var cIdxPath = "";
var cCatagory = this.getField("Catagory").value; switch(cCatagory) {
case "All":
cIdxPath = cPathRoot + "/Catalogs/All Forums.pdx";
break;
case "JS":
cIdxPath = cPathRoot + "/Catalogs/JavaScript Forum.pdx";
break;
case "LC":
cIdxPath = cPathRoot + "/Catalogs/LiveCycle Forum.pdx";
break;
case "FM":
cIdxPath = cPathRoot + "/Catalogs/Forms Forum.pdx";
break;
}
// Set up Search Options
search.matchCase = this.getField("CaseSensitive").isBoxChecked(0);
search.matchWholeWord = this.getField("WholeWord").isBoxChecked(0);
search.wordMatching = this.getField("MatchOpts").value;
// Perform Search
search.query(cSearchTxt, "Index", cIdxPath);
}
This sample is available for download in the Custom Search Page for Doc Library example. Remember what I said earlier about the folder structure. This example contains several files and will only work if the folder structure is extracted from the zip file with all the files, verbatim.
That’s all there is to it. To use the search object in your own code, you’ll need to modify what I’ve done here. Start simple by trying out the examples presented here and build on that by using the information provided in the Acrobat JavaScript Reference and the Acrobat JavaScript Guide, which can be found at https://www.adobe.com/devnet/acrobat.html.
Products covered: |
Acrobat 9 |
Related topics: |
JavaScript |
Top Searches: |
Edit PDF create PDF Action Wizard |
Try Acrobat DC
Get started >
Learn how to
edit PDF.
Ask the Community
Post, discuss and be part of the Acrobat community.
Join now >
0 comments
Comments for this tutorial are now closed.
Thom Parker
10, 2015-01-20 20, 2015JR, There are two obvious solutions. Embed the Index in the PDF, or put it on with the PDF in a local folder. If neither of these solutions are practical, then you might try either adding the website/domain to the list of trusted sites in the “Advance Security” preferences, or using a cross domain file. I don’t know how well either of these last two solutions will work, but they are both standard methods for adding trust to a PDF.
JR Williams
6, 2015-01-18 18, 2015Reader XI enhanced security has sandboxed/sandbagged the advanced catalog search presented in this article so it no longer works. Catalog index and files are in a network location. Is there an easy solution to overcome this, besides just turning off the Protected Mode (which LAN administrators oppose)?
Comments for this tutorial are now closed.